
那棵树看起来生气了
图解YOLOV3目标检测算法-源码分析(一 架构)
06/05
图解YOLOV3目标检测算法-源码分析(一 架构)
前言
目标检测算法
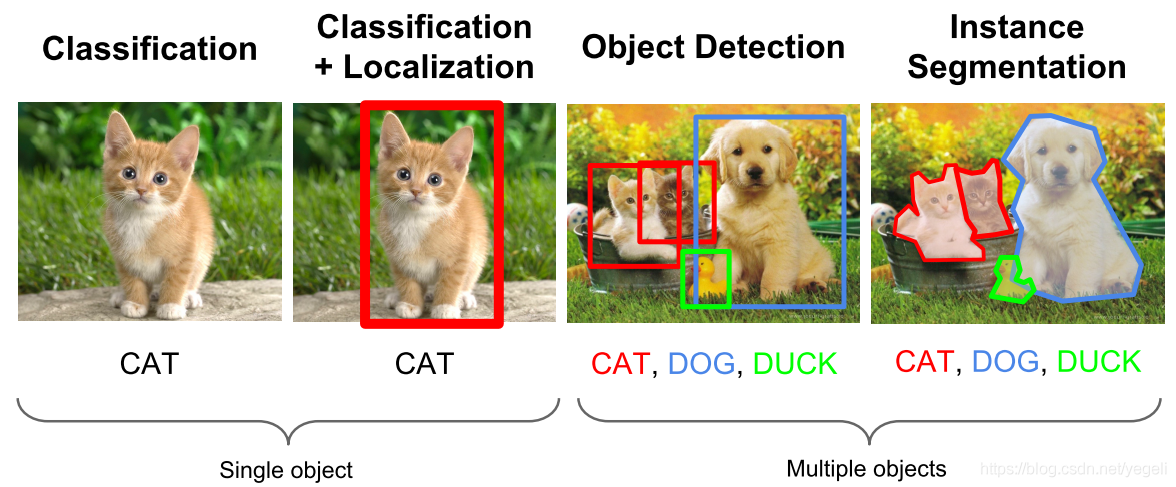
Tow Stage
先进行区域生成Region Proposal (RP),再通过卷积神经网络进行样本分类。
任务流程:特征提取 --> 生成RP --> 分类/定位回归。
常见tow stage目标检测算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN、R-FCN、MR-CNN、HyperNet、CRAFT、FPN、Mask R-CNN、、CoupleNet和MegDet等。
One Stage
不用RP,直接在网络中提取特征来预测物体分类和位置。
任务流程:特征提取–> 分类/定位回归。
常见的one stage目标检测算法有:OverFeat、YOLOv1、YOLOv2(YOLO9000)、YOLOv3、YOLOv4、YOLOv5、YOLOF、YOLOS、SSD和RetinaNet等。
YOLO是One Stage最具代表性的算法,集推理速度和准确性于一体,是我工作和学习中最常用的算法。下面将根据Github上开源代码分析YOLO算法系中最具代表的YOLOv3算法。
正文
YOLOv3
参考源码取自Github上一个Yolov3 Tensorflow实现 Github参考源码
为了理清YOLOv3大致框架,我根据源码画了该算法的架构图,
YOLOv3算法大致分为如下四部分
- Input
- Backbone
- Neck
- Prediction
如下图所示

Input
输入为3通道RGB图,shape为 4164163,当然不是固定的,可以根据情况调整
[-1, 416, 416, 3]Backbone ( darknet53 )
主干网络, Backbone主要是残差卷积,负责图像的特征提取
Yolov3的主干网络是可以随意替换,但笔者使用最多的还是darknet53。在Yolov3中的darknet53是去掉最终的全连接层的,由一个CBL,5个Res残差模块组成,如下图

1. CBL
CBL:Yolov3网络结构中的最小组件,由Conv+Bn+LeakyRelu激活函数三者组成。
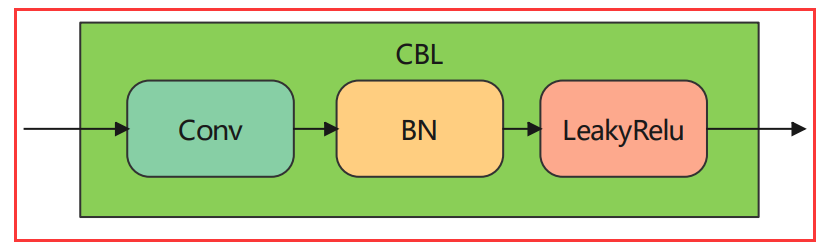
参考源码common.py 第11行,可以根据参数选择是否进行下采样和使用激活函数
def convolutional(input_data, filters_shape, trainable, name, downsample=False, activate=True, bn=True):
with tf.variable_scope(name):
if downsample:
pad_h, pad_w = (filters_shape[0] - 2) // 2 + 1, (filters_shape[1] - 2) // 2 + 1
paddings = tf.constant([[0, 0], [pad_h, pad_h], [pad_w, pad_w], [0, 0]])
input_data = tf.pad(input_data, paddings, 'CONSTANT')
strides = (1, 2, 2, 1)
padding = 'VALID'
else:
strides = (1, 1, 1, 1)
padding = "SAME"
weight = tf.get_variable(name='weight', dtype=tf.float32, trainable=True, shape=filters_shape,
initializer=tf.random_normal_initializer(stddev=0.01))
conv = tf.nn.conv2d(input=input_data, filter=weight, strides=strides, padding=padding)
if bn:
conv = tf.layers.batch_normalization(conv, beta_initializer=tf.zeros_initializer(),
gamma_initializer=tf.ones_initializer(),
moving_mean_initializer=tf.zeros_initializer(),
moving_variance_initializer=tf.ones_initializer(), training=trainable)
else:
bias = tf.get_variable(name='bias', shape=filters_shape[-1],
trainable=True, dtype=tf.float32,
initializer=tf.constant_initializer(0.0))
conv = tf.nn.bias_add(conv, bias)
if activate == True:
conv = tf.nn.leaky_relu(conv, alpha=0.1)
return conv在BackBone中,CBL紧接Input之后第一个单元如源码所示
input_data = common.convolutional(input_data, filters_shape=(3, 3, 3, 32), trainable=trainable, name='conv0')
2. Res Unit * 1
Res Unit
借鉴Resnet网络中的残差结构,让网络可以构建的更深。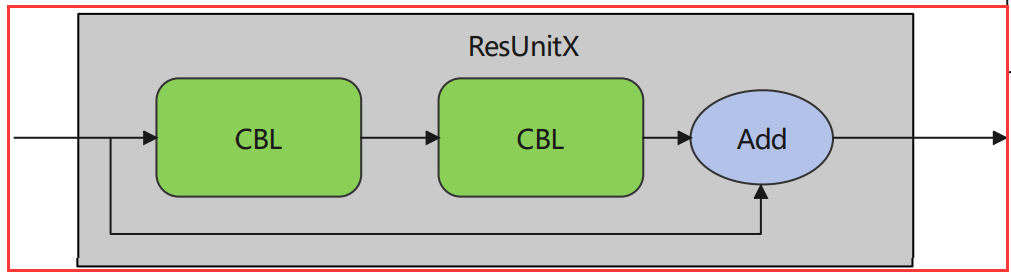
残差单元使用了两个连续的CBL,然后把最初的输入和CBL输出相加构成,如上图。
ResX
由一个CBL和X个残差组件构成,即一个CBL加X个Res Unit单元,它是YOLOv3中的大组件。每个Res模块前面的CBL都起到下采样的作用,经过5次Res模块后,得到的特征图是 416->208->104->52->26->13 大小。
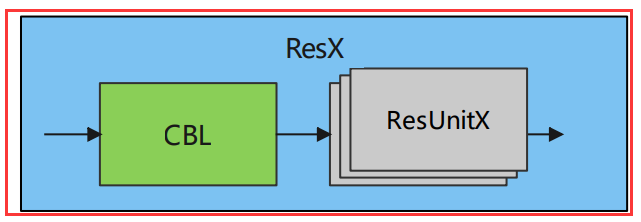
在源码中使用如下,参考 backbone.py第18行
input_data = common.convolutional(input_data, filters_shape=(3, 3, 32, 64), trainable=trainable, name='conv1', downsample=True) # 208*208*64
for i in range(1):
input_data = common.residual_block(input_data, 64, 32, 64, trainable=trainable, name='residual%d' % (i + 0))同理,下面的Res2、Res8、Res8、Res5
3. Res Unit *2
input_data = common.convolutional(input_data, filters_shape=(3, 3, 64, 128), trainable=trainable, name='conv4', downsample=True)
for i in range(2):
input_data = common.residual_block(input_data, 128, 64, 128, trainable=trainable, name='residual%d' % (i + 1))4. Res Unit *8
input_data = common.convolutional(input_data, filters_shape=(3, 3, 128, 256), trainable=trainable, name='conv9', downsample=True)
for i in range(8):
input_data = common.residual_block(input_data, 256, 128, 256, trainable=trainable, name='residual%d' % (i + 3))5. Res Unit *8
input_data = common.convolutional(input_data, filters_shape=(3, 3, 256, 512), trainable=trainable, name='conv26', downsample=True)
for i in range(8):
input_data = common.residual_block(input_data, 512, 256, 512, trainable=trainable, name='residual%d' % (i + 11))6. Res Unit *4
input_data = common.convolutional(input_data, filters_shape=(3, 3, 512, 1024), trainable=trainable, name='conv43', downsample=True)
for i in range(4):
input_data = common.residual_block(input_data, 1024, 512, 1024, trainable=trainable, name='residual%d' % (i + 19))Neck
BackBone 五次下采样后输出 13131024*80向量,然后作为Neck网络的输入(当然,中间还有些取样)
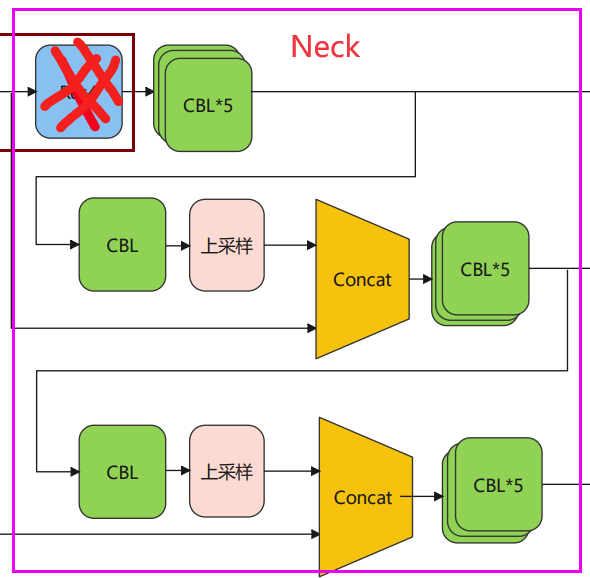
Y1
对于第一层输出, 见 yolov3.py第50行,这里连续五层CBL

input_data = common.convolutional(input_data, (1, 1, 1024, 512), self.trainable, 'conv52')
input_data = common.convolutional(input_data, (3, 3, 512, 1024), self.trainable, 'conv53')
input_data = common.convolutional(input_data, (1, 1, 1024, 512), self.trainable, 'conv54')
input_data = common.convolutional(input_data, (3, 3, 512, 1024), self.trainable, 'conv55')
input_data = common.convolutional(input_data, (1, 1, 1024, 512), self.trainable, 'conv56')
五层CBL处理后直接接上CBL+Conv,这里有些小伙帮可能会说,这不是两层CBL,其实并不是,看参数,第二个函数没有激活函数activate=False, bn=False,说明没有BN和activate,只是简单的Conv。
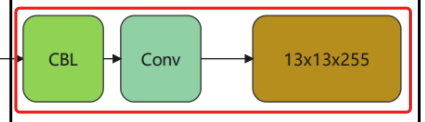
conv_lobj_branch = common.convolutional(input_data, (3, 3, 512, 1024), self.trainable, name='conv_lobj_branch')
conv_lbbox = common.convolutional(conv_lobj_branch, (1, 1, 1024, 3 * (self.num_class + 5)),
trainable=self.trainable, name='conv_lbbox', activate=False, bn=False)Y2
接着把刚刚最上层五层CBL的输出作为下一层的输入,CBL + 上采样 输出的结果和主干网络的C4输入Concat,最后接上个CBL*5 如图
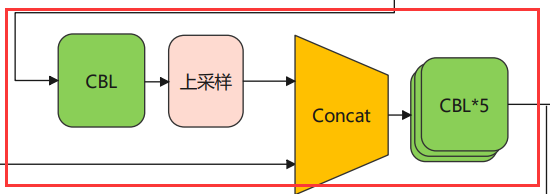
这个结构的输出便可以直接到预测节点了,经过上采样,输入的向量的大小已经变成 26*26了
Y3
对于第三层,采样上面同样的方法,见结构图 5252255
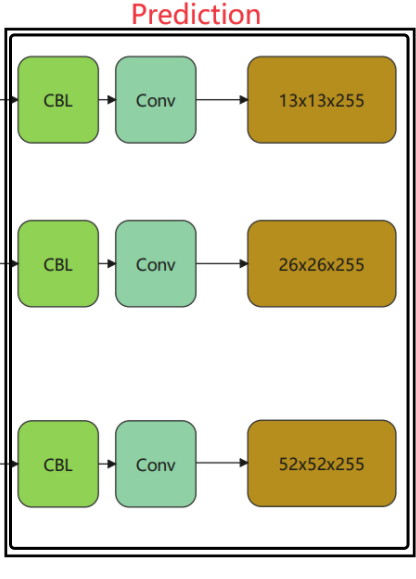
Prediction
最后Prediction为多次度融合特征,如下图
结尾
到此,Yolov3的基础架构就讲完了。后面的Decode和Loss留到下一篇再讲
图解YOLOV3目标检测算法-源码分析(二 预测框)
图解YOLOV3目标检测算法-源码分析(三 Loss)
参考


三合一收款
下面三种方式都支持哦





